huggingface 大模型BERT文本分类之情感分析
目标
本文通过huggingface的Transform类进行BERT的文本分类代码训练与验证,数据集采用网上整理包括正向和负向评论的携程网数据
通过实战完整地去掌握完整代码步骤,包括:
数据的加载创建数据集划分训练集和验证集创建模型和优化器模型的训练模型的验证模型的预测
实现当输入一个对酒店的评价的一段文字,模型输出对于这个酒店的分析,判断是正向评价还是负面评价
BERT适用场景
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer的预训练语言模型,它在自然语言处理(NLP)领域中具有广泛的应用,以下是一些BERT特别适用的场景:
- 1、文本分类:BERT可以用于情感分析、主题分类、垃圾邮件检测等文本分类任务。它能够捕捉到文本中细微的语义差异,从而实现更准确的分类。
- 2、问答系统:BERT可以用于构建问答系统,它能够理解问题的上下文,并在大量文本中找到正确的答案。
- 3、命名实体识别(NER):在NER任务中,BERT能够识别文本中的特定实体,如人名、地点、组织等。
- 4、机器翻译:虽然BERT最初是为英语设计的,但它也可以通过多语言预训练模型来支持机器翻译任务。
- 5、文本摘要:BERT可以用于生成文本的摘要,无论是提取式摘要还是生成式摘要。
- 6、语言模型评估:BERT可以用于评估其他语言模型的性能,通过比较预训练模型和目标模型的表示。
- 7、文本相似度:BERT可以用于计算文本之间的相似度,这在推荐系统、搜索引擎优化等领域非常有用。
- 8、对话系统:BERT可以用于构建对话系统,理解用户的意图,并生成合适的回复。
- 9、文档分类:在法律、医疗等领域,BERT可以用于对文档进行分类,帮助专业人士快速定位信息。
- 10、文本生成:虽然BERT主要用于理解语言,但它也可以用于文本生成任务,如续写故事、生成诗歌等。
- 11、语义匹配:BERT可以用于比较两个句子的语义相似度,这在语义搜索、信息检索等领域非常有用。
- 12、文本纠错:BERT可以用于检测和纠正文本中的错误,提高文本质量。
- 13、多任务学习:BERT可以同时处理多个NLP任务,通过共享表示来提高各个任务的性能。
本次数据集介绍
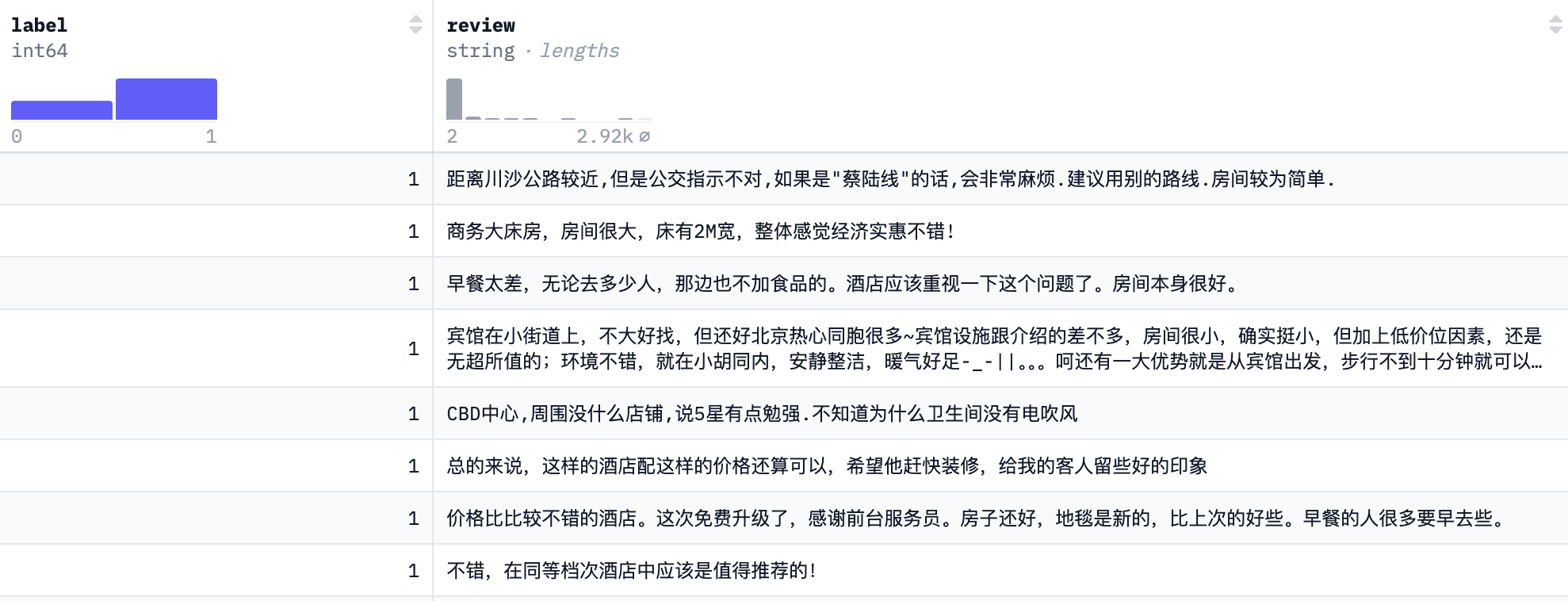
数据集来源于网络整理的携程网数据, 包括7000 多条酒店评论数据,5000 多条正向评论,2000 多条负向评论
地址:https://github.com/SophonPlus/ChineseNlpCorpus/tree/master/datasets/ChnSentiCorp_htl_all
字段说明
| 字段 | 说明 |
|---|---|
| label | 1 表示正向评论,0 表示负向评论 |
| review | 评论内容 |
硬件环境
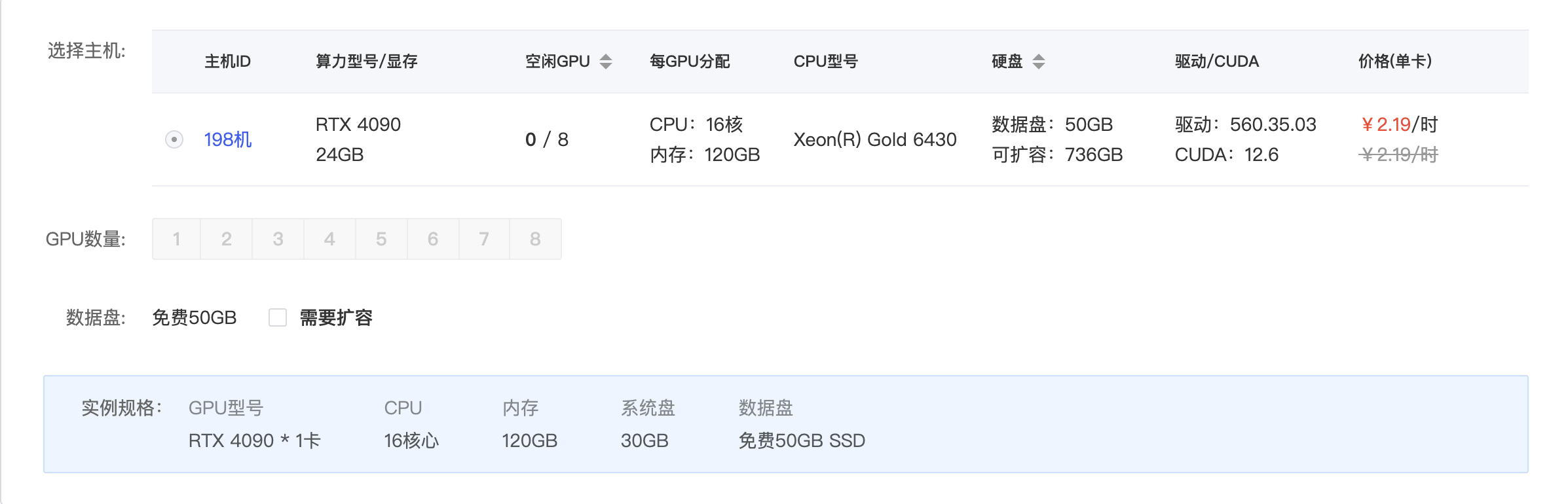
本例比较简单,好点配置的电脑应该都跑得了,但为了熟悉还是用GPU来玩一下,熟悉一下方便以后租借算力。
本次实验使用AutoDL AI算力云租借算力,采用GPU卡进行训练,使用Ubuntu 24.04LTS版本,Python使用Python 3.12.3版本
基本的硬件配置如下:
- CPU: 16 核,Xeon(R) Gold 6430
- 内存: 120 GB
- GPU: Nvidia RTX 4090 / 24 GB